2026/01/23 4:27
SSH は実際には「1 回のキー入力につき 100 パケットを送る」わけではありません。送信されるパケット数は、SSH プロトコル設計とネットワーク状況に応じて決まります。 --- ## 「1 キーストローク=100 パケット」に見える理由 | # | 原因 | 説明 | |---|------|------| | 1 | **パケットの分割(フラグメンテーション)** | SSH のトランスポート層はデータを固定長ブロック(既定では 64 KiB)に分割します。<br>キー入力で生成される数バイトがそのブロックサイズまでパディングされ、1 パケットとして送信されます。 | | 2 | **暗号化オーバーヘッド** | 各パケットには暗号ヘッダー・MAC(メッセージ認証コード)が付加され、場合によっては圧縮ヘッダーも含まれます。<br>これらの余分なデータが「実際に送信された」パケット数を増やすように見える原因となります。 | | 3 | **ネットワークフラグメンテーション(MTU)** | 大きい SSH パケットは、ネットワークスタックによって MTU サイズ(約 1500 バイト)ごとに分割されます。<br>1 本の SSH パケットが複数の IP フラグメントへ変換され、各フラグメントが「別個のパケット」として計測されることがあります。 | | 4 | **TCP ウィンドウと再送** | 小さなパケットは高いレイテンシ環境では ACK(確認応答)や再送を頻繁に発生させ、観測上のパケット数が増加します。 | | 5 | **サーバ側バッファリング** | サーバは複数のキー入力をまとめて送信する前にバッファリングし、その後いくつかのパケットに分割して転送することがあります。 | --- ## 結論 「1 キーストローク=100 パケット」という誤解は、SSH のブロックベース設計、暗号化オーバーヘッド、MTU によるフラグメンテーション、およびネットワーク挙動の組み合わせによって生じます。プロトコル自体が意図的にリンクを詰め込むわけではありません。
RSS: https://news.ycombinator.com/rss
要約▶
Japanese Translation:
著者のSSHベースのTUIゲーム(bubbletea + wish)は約2 000人の同時プレイヤーを想定して設計されましたが、予期せぬ高CPUと帯域幅使用量に悩まされました。「your screen is too small」というテストハーネスはリソース使用量を約50%削減しました。ポート 22でのパケットキャプチャでは約413 kパケットが確認され、274 k(66 %)が36バイトのチューブ、139 k(34 %)がゼロバイトACK、数個の72バイトパケットでした。この36バイトメッセージは単一キー入力SSHセッションでも約20 msごとに現れました。
ssh -vvvObscureKeystrokeTiming=noサーバー側のオーバーヘッドを除去するため、著者は
golang.org/x/crypto/ssh[email protected]著者はまた、LLMs(Claude Code)がデバッグを支援したものの、人間による監督がパッチを特定し適用するために不可欠であると指摘しています。将来的にはよりターゲットを絞った最適化が検討されるかもしれませんが、現在の修正はリソース集約型TUIアプリケーションユーザーのスケーラビリティとレイテンシを既に改善しています。
本文
なぜ私が気にするのか?
2026 年 1 月 22日
TUI(BubbleTea と Wish で構築した)上でゲームデータを送る SSH セッション中、1 回だけキー入力しただけで生成されるパケット数の膨大さに驚きました。
1. tcpdump のサンプル出力
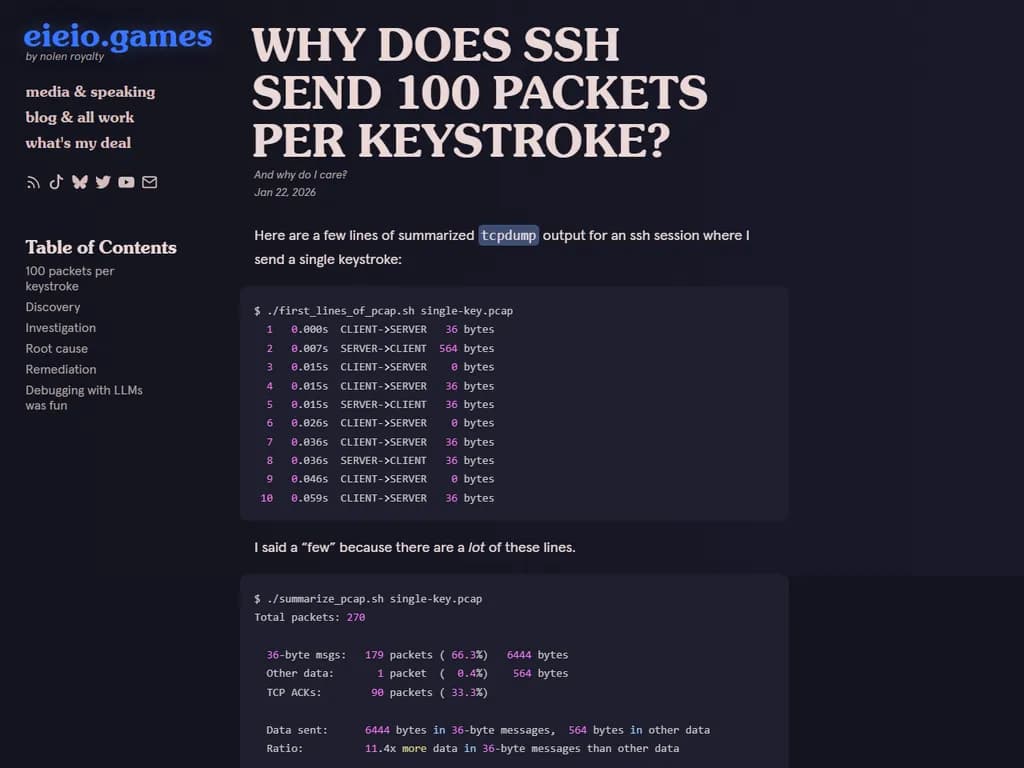
$ ./first_lines_of_pcap.sh single-key.pcap 1 0.000s CLIENT->SERVER 36 bytes 2 0.007s SERVER->CLIENT 564 bytes 3 0.015s CLIENT->SERVER 0 bytes 4 0.015s CLIENT->SERVER 36 bytes 5 0.015s SERVER->CLIENT 36 bytes 6 0.026s CLIENT->SERVER 0 bytes 7 0.036s CLIENT->SERVER 36 bytes 8 0.036s SERVER->CLIENT 36 bytes 9 0.046s CLIENT->SERVER 0 bytes 10 0.059s CLIENT->SERVER 36 bytes
summary_pcap.sh$ ./summarize_pcap.sh single-key.pcap Total packets: 270 36-byte msgs: 179 packets (66.3%) 6444 bytes Other data: 1 packet (0.4%) 564 bytes TCP ACKs: 90 packets (33.3%) Data sent: 6444 bytes in 36‑byte messages, 564 bytes in other data Ratio: 11.4x more data in 36‑byte messages than other data Data packet rate: ~90 packets/second (avg 11.1 ms between data packets)
質問: なぜ 1 回のキー入力でこんなに多くのトラフィックが発生するのでしょうか?
2. スクリプト
# first_lines_of_pcap.sh tshark -r "$1" \ -T fields -e frame.number -e frame.time_relative -e ip.src -e ip.dst -e tcp.len | \ awk 'NR<=10 { dir = ($3 ~ /71\.190/ ? "CLIENT->SERVER" : "SERVER->CLIENT"); printf "%3d %6.3fs %-4s %3s bytes\n", $1, $2, dir, $5 }'
# summarize_pcap.sh tshark -r "$1" -Y "frame.time_relative <= 2.0" \ -T fields -e frame.time_relative -e tcp.len | awk ' { count++ payload = $2 if (payload == 0) { acks++ } else if (payload == 36) { mystery++ if (NR > 1 && prev_data_time > 0) { delta = $1 - prev_data_time sum_data_deltas += delta data_intervals++ } prev_data_time = $1 } else { game_data++ game_bytes = payload if (NR > 1 && prev_data_time > 0) { delta = $1 - prev_data_time sum_data_deltas += delta data_intervals++ } prev_data_time = $1 } } END { print "Total packets:", count printf " 36-byte msgs: %3d packets (%5.1f%%) %5d bytes\n", mystery, 100*mystery/count, mystery*36 printf " Other data: %3d packet (%5.1f%%) %5d bytes\n", game_data, 100*game_data/count, game_bytes printf " TCP ACKs: %3d packets (%5.1f%%)\n", acks, 100*acks/count printf " Data sent: %d bytes in 36-byte messages, %d bytes in other data\n", mystery*36, game_bytes printf " Ratio: %.1fx more data in 36-byte messages than other data\n", (mystery*36)/game_bytes avg_ms = (sum_data_deltas / data_intervals) * 1000 printf " Data packet rate: ~%d packets/second (avg %.1f ms between data packets)\n", int(1000/avg_ms + 0.5), avg_ms }'
3. 発見
- 私は SSH 上で動く高速ゲームを構築しており、80×60 の TUI を 秒間10回 更新しています。
- ターゲットは同時に 2,000 人以上のプレイヤー → 秒間約 1 億セル更新です。
- テストハーネスが壊れ、サーバ側が通常ゲームデータではなく「画面が小さい」メッセージだけを送っていたため、CPU と帯域幅は 約 50 % 割り込まれました(100 % ではありません)。
で 壊れている場合 と 正常な場合 のトラフィックを比較しました。tcpdump
timeout 30s tcpdump -i eth0 'port 22' -w with-breaking-change.pcap timeout 30s tcpdump -i eth0 'port 22' -w without-breaking-change.pcap
- 「壊れた」キャプチャは 36 バイトのパケットが全体の 66 %、ゼロバイト ACK が 34 %、数個の 72 バイトパケットを含んでいました。
これらの 36 バイトパケットは約 20 ms 間隔で届いています。
4. 根本原因 – SSH のキー入力タイミング偽装
ssh -vvvdebug3: obfuscate_keystroke_timing: starting: interval ~20ms debug3: obfuscate_keystroke_timing: stopping: chaff time expired (49 chaff packets sent) debug3: obfuscate_keystroke_timing: starting: interval ~20ms debug3: obfuscate_keystroke_timing: stopping: chaff time expired (101 chaff packets sent)
- 2023 年以降、OpenSSH は キー入力タイミングの偽装 を追加し、タイプパターンを隠します。
- キーが押されるたびに ~20 ms ごとに「チャフ」パケット(
)を送信します。SSH2_MSG_PING - これらが今回観測した 36 バイトのメッセージです。
ゲームでは遅延が重要なため、このオーバーヘッドは望ましくありません。
5. 対策
クライアント側で無効化(テスト時に機能)
ssh -o ObscureKeystrokeTiming=no user@host
- CPU 使用率が劇的に低下しました。
- ボットは有効なデータを受け取り続けました。
しかし、ユーザーがこのオプションを知って設定するのは難しいかもしれません。
サーバ側で Go SSH ライブラリを修正
- この偽装は Go の
にあるcrypto/ssh
拡張に紐づいています。[email protected] - ちょっとしたコミット(ping/pong 機構の追加)を戻すと、拡張広告が消えます。
をフォークし、その変更を revert してgolang.org/x/crypto/ssh
ディレクティブで利用:replace
// go.mod replace golang.org/x/crypto/ssh => ../my-ssh-fork
- パッチ適用後の結果は次の通りです。
| 指標 | Before | After |
|---|---|---|
| CPU | 29.90 % | 11.64 % |
| システムコール | 3.10 s | 0.66 s |
| 暗号処理 | 1.6 s | 0.11 s |
| 帯域幅 | ~6.5 Mbit/s | ~3 Mbit/s |
CPU 使用率が 50 % 超減 – スケーラビリティ向上に大きく貢献。
6. LLM 辅助デバッグへの思索
- Claude Code を使って pcap を解析・要約したのは 楽しく効率的でした。
- エージェントが実行したコマンドを確認できるので、メンタルモデルが保てました。
- それでも ChatGPT の曖昧な回答に対して指摘し、Go ライブラリのフォークを考慮させる必要がありました。LLM は「助け」、最終的には人間の洞察が不可欠です。
結論
予期せぬ 36 バイトパケットは SSH のキー入力タイミング偽装チャフ でした。
クライアント側で無効化するか、Go SSH ライブラリを修正してこの機能を排除すれば、CPU と帯域幅のオーバーヘッドが大幅に削減され、数千人同時プレイヤーでも遅延を抑えつつスケールできます。