2025/12/24 9:27
高性能C++ハッシュテーブル:SIMDメタデータグループスキャンを用いた実装
RSS: https://news.ycombinator.com/rss
要約▶
Japanese Translation:
GroupedSIMDElasticは、軽量でヘッダーオンリーのC++17ハッシュテーブルです。500 k要素を超える大規模テーブルに対して、現在最先端とされる
ankerl::unordered_denseh + 16×n²insertfindcontainsoperator[]size()capacity()load_factor()max_probe_used()実装はSSE2のみを必要とし、外部依存はなくMITライセンスで配布されています。Google の Swiss Tables および 2025年2月に発表された「Elastic Hashing」論文(Yao の均一探索仮説を否定したもの)からインスピレーションを得ています。実験結果では、散在型 SIMD ガザリはグループ化探索より約5倍遅いことも示されています。
現在の制限点としては、挿入オーバーヘッドが高い、削除機能がない、固定容量(リサイズ不可)、ARM NEON サポートが欠如していることがあります。将来的にはこれらの機能追加とプラットフォーム対応拡張を予定しています。ソースファイルは
grouped_simd_elastic.hpphybrid_elastic.hppbenchmark_final_sota.cppINSIGHTS.mdEXPERIMENT_RESULTS.md本文
グループ化された SIMD ハッシュテーブル – スケールでの最先端ハッシング
Dimitris Mitsos & AgentsKB.com によって作成
概要
高性能な C++ ハッシュテーブルで、テーブルサイズが約 500 k 要素を超え、ワークロードが検索中心の場合に、最先端(Robin Hood)実装 ankerl::unordered_dense を上回ります。主なアイデアは グループ化プロービング:16 個の連続したスロットを 1 回の SIMD ロードで走査し、その後次のグループへジャンプします。
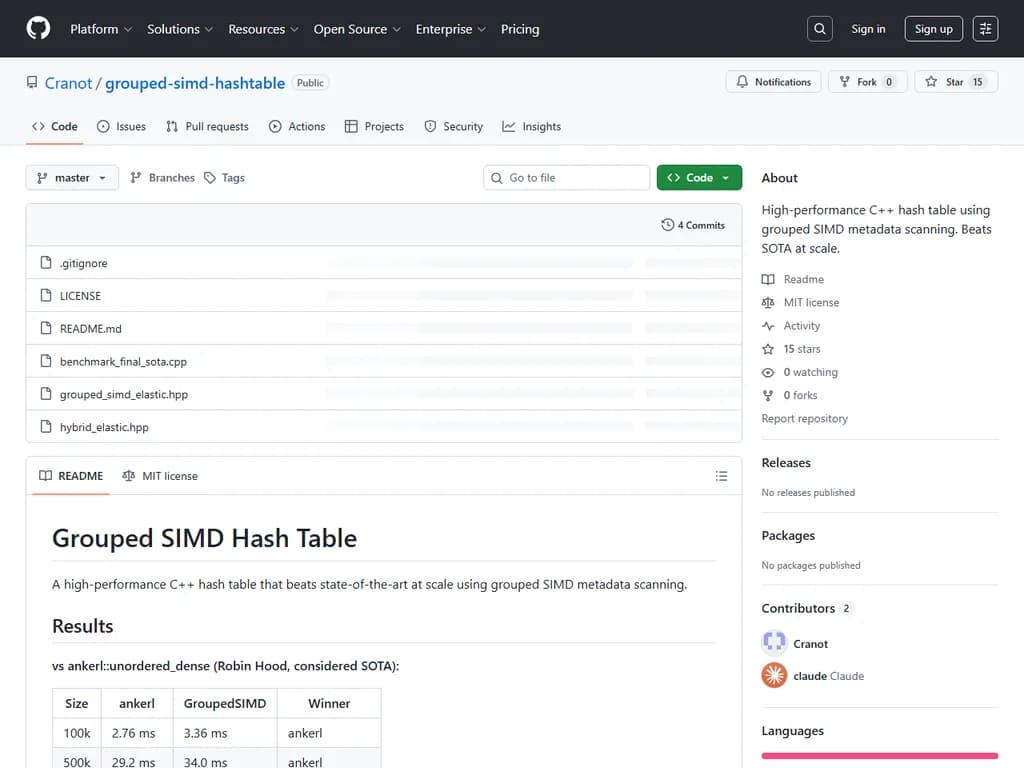
結果
| サイズ | ankerl (ms) | GroupedSIMD (ms) | 勝者 |
|---|---|---|---|
| 100 k | 2.76 | 3.36 | ankerl |
| 500 k | 29.2 | 34.0 | ankerl |
| 1 M | 72.3 | 71.9 | GroupedSIMD |
| 2 M | 157.4 | 156.3 | GroupedSIMD |
1 M 要素(80 % 負荷)での操作別内訳
| 操作 | ankerl (ms) | GroupedSIMD (ms) | スピードアップ |
|---|---|---|---|
| Insert | 50.8 | 70.1 | 0.72× |
| Lookup Hit | 104 | 61.5 | 1.69× |
| Lookup Miss | 5.4 | 4.5 | 1.21× |
使用推奨:テーブルサイズ > 500k、検索中心のワークロード。
挿入オーバーヘッド(0.72×)は、検索が支配的であれば許容範囲です。
使い方
#include "grouped_simd_elastic.hpp" // 1M 要素用に容量を確保 GroupedSIMDElastic<uint64_t, uint64_t> table(1200000); // 挿入 table.insert(key, value); // 検索 uint64_t* result = table.find(key); if (result) { // 見つかった: *result が値 } // 存在確認 if (table.contains(key)) { /* … */ } // 代入演算子 table[key] = value;
動作原理
SIMD とハッシュテーブルの問題点
二次探査は散らばったメモリアクセスを行います:
h, h+1, h+4, h+9, h+16, h+25…SIMD を使うには 16 個のランダムな位置を集める必要があり、スカラーコードより遅くなります。
解決策:グループ化プロービング
16 個の連続したスロット を 1 グループとしてまとめ、その後次のグループへジャンプします:
Group 0: [h+0 … h+15] ← SIMD スキャン(1 ロード) Group 1: [h+16…h+31] ← SIMD スキャン(1 ロード) Group 2: [h+32…h+47] ← SIMD スキャン(1 ロード)
各グループ内で SSE2 は 16 バイトのメタデータを約 3 命令で走査します:
__m128i meta = _mm_loadu_si128((__m128i*)&metadata_[base]); __m128i matches= _mm_cmpeq_epi8(meta, target); uint32_t mask = _mm_movemask_epi8(matches);
これは Google の Swiss Tables が採用した洞察と同じです。
メタデータ形式
各スロットは 1 バイトのメタデータタグ を持ちます:
| ビット | 意味 |
|---|---|
| 7 | 占有フラグ (1 = 占有) |
| 0–6 | 7 ビットハッシュフラグメント |
これにより、キー比較前に 127/128 の非一致を除外できます。
API リファレンス
template <typename K, typename V, typename Hash = std::hash<K>> class GroupedSIMDElastic { public: explicit GroupedSIMDElastic(size_t capacity, double delta = 0.15); bool insert(const K& key, const V& value); V* find(const K& key); const V* find(const K& key) const; bool contains(const K& key) const; V& operator[](const K& key); // 未登録ならデフォルト挿入 size_t size() const; size_t capacity() const; double load_factor() const; size_t max_probe_used() const; };
要件
- C++17 以降
- SSE2 対応(すべての x86‑64 CPU に標準)
- ヘッダーオンリー、外部依存なし
ベンチマーク
# コンパイル g++ -O3 -march=native -msse2 -std=c++17 \ -o benchmark benchmark_final_sota.cpp # 実行 ./benchmark
研究の軌跡
実装は 2025 年 2 月に公開された Elastic Hashing 論文を探索する過程で進化しました。この論文は、ヤオが提唱した 40 年前からの「均一探査」仮説を覆しました。
| バリアント | 結果 | 学び |
|---|---|---|
| 非貪欲プロービング | 1M で 5% 速い | O(1) 平均遅延が機能 |
| SIMD(散乱) | 0.18× (5× 遅い) | Gather オーバーヘッドが殺す |
| メモリプリフェッチ | 0.41× (2.5× 遅い) | ハードウェアプリフェッチャーが勝つ |
| Robin Hood | ミスで 2×速い | プローブ分散が重要 |
| グループ化 SIMD | 検索で 1.5×速い | 隣接アクセスが SIMD を可能に |
鍵となる洞察:SIMD は連続メモリアクセスを必要とします。二次探査はアクセスを散らすため、SIMD が機能しません。グループ化プロービング(Swiss Tables のアプローチ)がこれを解決します。
制限とトレードオフ
| トレードオフ | 影響 | 備考 |
|---|---|---|
| 挿入オーバーヘッド | ankerl と比べ 0.72× | 非貪欲候補収集 |
| 小規模テーブル | 500k 未満で劣る | 約 500k–1M 要素で交差点 |
| 削除なし | 実装未完了 | 今後予定 |
| リサイズなし | 固定容量 | 事前にサイズ決定 |
| SSE2 のみ | x86‑64 限定 | ARM NEON バージョンは無し |
技術的詳細:なぜ二次グループジャンプか?
グループはクラスタリングを避けるために二次ジャンプを採用します:
Group 0: h + 16×0² = h Group 1: h + 16×1² = h+16 Group 2: h + 16×2² = h+64 Group 3: h + 16×3² = h+144
線形ジャンプ(h, h+16, h+32…)は、プローブシーケンスの重複により挿入失敗率が 42% になるためです。二次ジャンプでグループをテーブル全体に分散させることで、すべてのスロットへ到達可能になります。
ファイル一覧
– 本実装(配布対象)grouped_simd_elastic.hpp
– 非 SIMD ベースラインhybrid_elastic.hpp
– ankerl とのベンチマークbenchmark_final_sota.cpp
– 完全研究ログINSIGHTS.md
– 全実験データEXPERIMENT_RESULTS.md
ライセンス
MIT
謝辞
- Swiss Tables(Google)– グループ化プロービングの洞察
- ankerl::unordered_dense – SOTA ベンチマークベースライン
- Elastic Hashing 論文 – 理論的基盤