2025/12/11 23:45
From text to token: How tokenization pipelines work
RSS: https://news.ycombinator.com/rss
要約▶
Japanese Translation:
記事では、現代の検索エンジンが生テキストを検索可能なデータに変換する方法として、まずトークン化し、その後一連のフィルタでクリーンアップするプロセスについて説明しています。最初にテキストは正規化されます:大文字小文字を統一し、アクセント記号を除去して「Café」を「cafe」に変換します。トークナイズでは入力が単語に分割されます;単純な空白/句読点のトークナイザーが一般的ですが、エンジンごとに挙動は異なります。Lucene は「it’s」を
[it's][it, s]トークン化後、「the」「and」「of」などのストップワードが除去され、サンプル文のトークン数は10から8に減少します。次にステミング(Porter/Snowball など)を適用し、語形変化を統一して「jumped」を「jump」に変換します。この結果、「databas」「lazi」「cafe」などの語幹が得られます。また、より正確だが遅いとされる形態素解析(レマタイズ)も紹介されています。
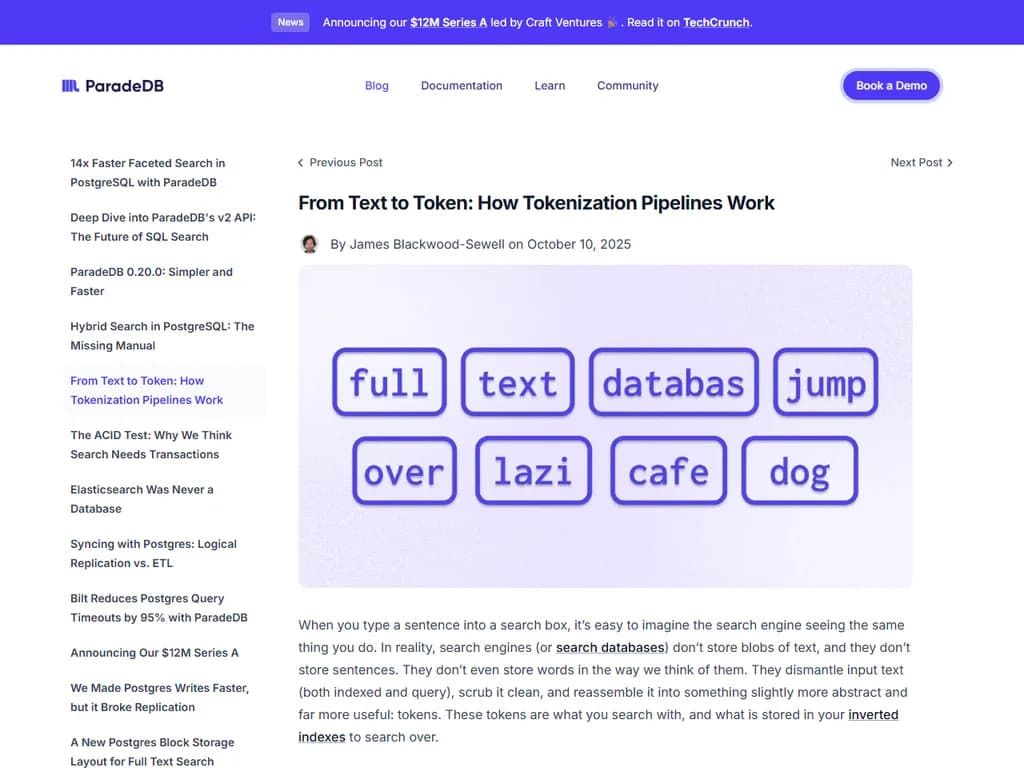
例文に対する最終トークンセットは
fulltextdatabas jumpoverlazicafedogdatabasjumpLucene、Tantivy/ParadeDB、Postgres full‑text などの検索エンジンは、これらのフィルタを組み合わせ可能な構成要素として公開しており、必要に応じて有効化・無効化・順序変更ができます。ストップワードリストは設定可能で、ストップワード除去後も位置情報は保持されるため、高精度の関連性調整と高速なインデックス作成を両立できます。
本文
ジェームズ・ブラックウッド‑スウェル著 – 2025年10月10日
検索エンジンに文章を入力するとき、あなたが行っていることと同じ視点で検索エンジンがそれを見ているかのように想像しやすいですが、実際には検索エンジン(あるいは検索データベース)はテキスト・バイオグラムではなく、単語を私たちが思っている通りに保存しているわけではありません。
代わりに、入力されたテキスト(索引付けされているか否か)を分解し、きれいに洗練された「トークン」という形で再構築します。この トークン が検索対象となり、インデックス化された情報が保存されています。
パイプラインの流れ
各ステップで少しずつ読んで― パイコ―‐ ? 長い先
We need to translate the article into Japanese, keeping length roughly same. Provide full translation.ジェームズ・ブラックウッド‑スウェル 著 – 2025年10月10日
検索ボックスに文を入力すると、エンジンがまるで自分の目でその内容を読んでいるかのように想像しやすいですが、実際には検索エンジン(あるいは検索データベース)は「テキストブロブ」や「文」をそのまま保存しているわけではありません。単語も私たちが思っている形で格納されているとも限りません。代わりに、入力された文字列を分解し、不要な部分を取り除き、少し抽象化した トークン に再構築します。このトークンこそが検索の対象となり、インバーテッド・インデックスに保存されます。
パイプラインを実際に追う
パイプラインを一つずつゆっくり見ていきましょう。言語がどのように分解され再構築されるか、そしてその結果が検索にどう影響するかを確認します。今回のテストケースは「The quick brown fox jumps over the lazy dog」のひねりを加えたものです。トークナイズを面白くする要素(大文字・句読点・アクセント・パイプラインを通るうちに変化する語)すべてが揃っています。
オリジナルテキスト
The full‑text database jumped over the lazy café dog.
1. 大文字と記号のフィルタリング(ケース&フォールディング)
まず、テキストを分解する前に不要なものを除外します。通常は次の作業を行います。
- 全ての文字を小文字へ変換
- アクセントやダイアクリット記号を基本形に戻す(例: résumé, façade, Noël → resume, facade, noel)
このステップで文字が正規化され、トークナイズ前の準備が整います。
Café は cafe に、résumé は resume になるためです。小文字化は「Database」と検索した際に database と一致させる一方で、オリーブという名前とオリーブ(野菜)を混同してしまうなどの副作用が出ることもあります。ほとんどのシステムではこのトレードオフを受け入れています:偽陽性よりも見逃しは少ない方が好ましいです。ただし、コード検索では例外で、camelCase や PascalCase などのケース感度を維持することがあります。
小文字化&アクセント除去後
the full-text database jumped over the lazy cafe dog
2. テキストを検索可能な単位に分割(トークナイズ)
ここではフィルタリング済みのテキストを「インデックスできる単語」に変換します。英語で最も一般的なのは、空白と句読点で区切るシンプルな スペース+ポン… です。
分割後の結果
the fulltext database jumped over the lazy cafe dog
※他のシステムでは例外があるかもしれません。例えば Lucene のトークナイザーは it’s を
[it’s][it, s]トークナイザ―の三種類
| クラス | 役割 | 主な利用例 |
|---|---|---|
| ワード指向 | 単語境界でテキストを分割。空白トークナイザーや、非英語文字セットに対応した高度な言語感知型トークナイザーが含まれる。 | 単語単位で検索したいとき |
| 部分語 | 文字列を n‑gram やエッジ・n‑gram に分割。オートコンプリートやファジーマッチに有効だが、ノイズが増えることも。 | 補完機能や曖昧検索で利用 |
| 構造化テキスト | URL、メールアドレス、ファイルパスなど特定フォーマットを扱う。意味のある区切りを保持しつつ、一般的なトークナイザーが破壊してしまうようなパターンを処理。 | プロソー(非プロズテキスト)を含むコンテンツで必要 |
今回の例ではシンプルな空白トークナイザーを使います。
3. ストップワードでノイズ除去
「the」「and」「of」「are」など、検索価値が低い語は ストップワード と呼ばれます。検索エンジンはこれらをほぼ完全に捨てることで、残りの語句に重みを置きやすくします。
ストップワード除去後
fulltext database jumped over lazy cafe dog
ストップワードを削除するとトークン数が 10 から 8 に減り、意味的な重み付けが高まります。
リスク: 「The …」で始める名前(例:「The Who」を検索したときに the が必要になる場合があります。ストップワードリストは設定で調整可能です。
4. ステム化(語形変換)でルートへ
ステム化は単語を共通の根底へ落とし込む作業です。
ステム化後
fulltext databas jumped over lazi cafe dog
- jumped → jump
- lazy → lazi
- database → *databas
これらの形は実際に存在しない単語でも、検索時に「jumping」「jumped」「jumps」などを jump に統一してマッチさせます。
トークナイズが重要な理由
トークナイズ自体は華やかではありませんが、検索の根幹です。dogs が dog と一致しない、あるいは jumping が jump にヒットしないといった問題を防ぎます。スコアリング・ランキング・関連性評価すべてに影響しますので、正確なトークンが作られることが何より重要です。
ぜひ体験してみてください
Parade DB を使って、モダンな検索データベースがどのようにトークナイズを行うか確認しましょう。